一連の記事→wordpressテーマをカスタマイズしよう Archives – aoringo works
今回は記事本文から抜粋を自動で作る機能を作りたいと思います。
ともあれ、「今の時点で抜粋自動でできてるじゃん?」というのもわかります。わかりますが、「必ずしも冒頭文をもってきもていいわけではない」という事ですよ。
例えば私は本の感想を書くときに本のリンク→紹介文→感想、とするのですが、このままではリンクもしくは紹介文が抜粋にはいってしまいます。
こんなの・・・こんなのってないよ・・・・っ!!!
というわけで抜粋はしっかり設定してあげる必要があるんですよね。まんだむ。
BGMは任意ラヂヲです。なつかしいー。
.
 |
プラグイン API/フィルターフック一覧 – WordPress Codex 日本語版 |
さて、目標の機能を取り付けるために何を利用するのか。大抵はcodexにのってます。
「ふぃるたーふっく」って何さ。なんでしょうね。処理の間に挟まれる処理、みたいなもんですよきっと。私はそういう感じで理解してます。ダメですかね?
とりあえず、
content_edit_pre(投稿記事本文)
excerpt_edit_pre(記事抜粋)
title_edit_pre(記事タイトル)
なんかそれらしいものがありますよ。説明も「各データが編集画面に表示される前に適用される。」とあります。きっとこういうことですかね。
新規作成→excerpt_edit_pre→編集画面→下書き→excerpt_edit_pre→編集画面→投稿
そうであろうと仮定してとりあえずテストコードを組んでみます。
function replace_post_exp($exp) {
vbt($exp);
return $exp;
}
add_filter('excerpt_save_pre', 'replace_post_exp');
これでよし、です。「excerpt_save_pre」が発動するタイミングで「replace_post_exp」という関数が動作する、というコードです。中身は前回作った「vbt」だけ。というわけで、
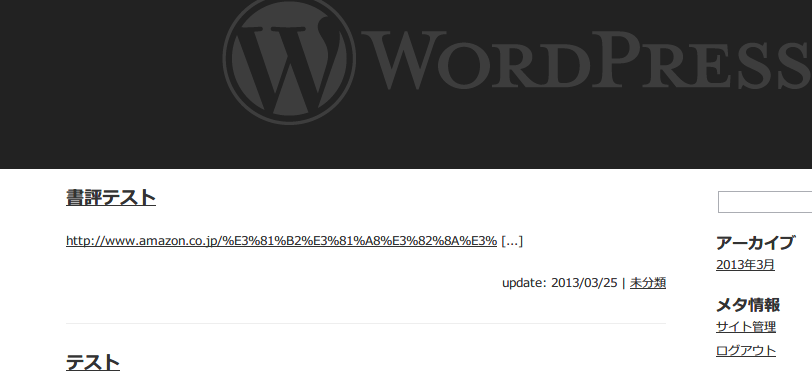
まず新規追加をクリック。

作成されました。新規作成のタイミングで既に発動していることがわかります。
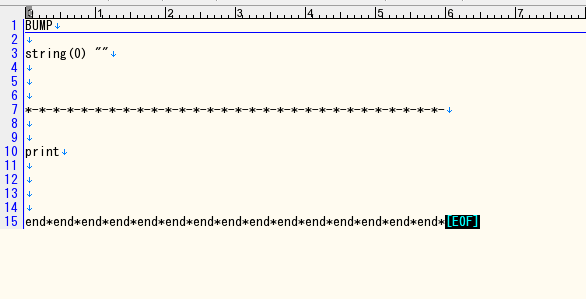
抜粋の中身は空なのでもちろん空。
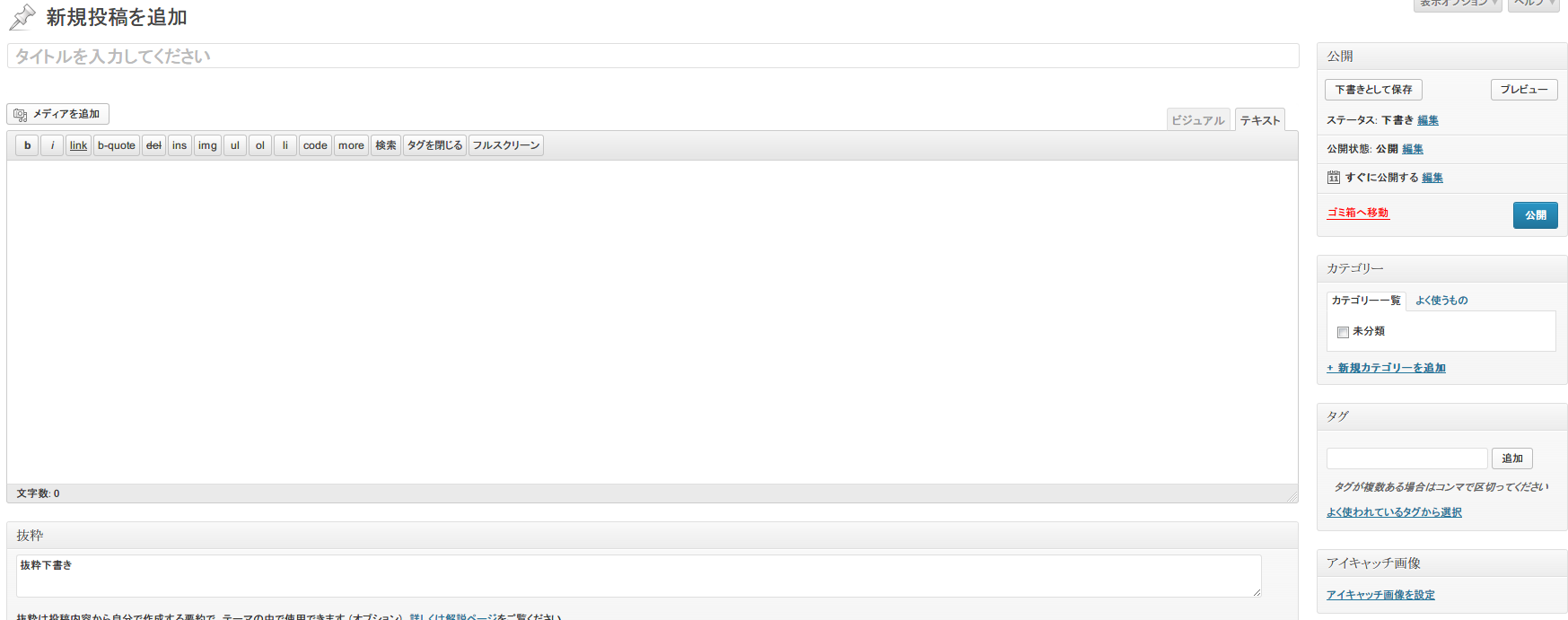
次は下書き。抜粋には「抜粋下書き」といれてあります。
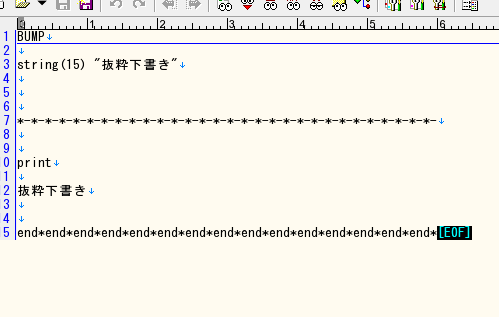
ちゃんと入ってます。これでこの関数の挙動が確認できましたね。さてはて、こいつを利用して記事本文を弄くり、返してやれば抜粋の自動化はできそうでありますな。
じゃあ記事本文はどうやってもってくるんじゃい。こいつぁ抜粋しかもってへんど。どこに本文があるってゆうんじゃ。
あいやまたれい、wordpressは色々なデータを$_POSTでやりとりしてるんでまんがな!!(何
まあつまり、replace_post_expが働いてる横で、下書きボタンを押した瞬間に$_POSTで色々なデータも飛んでいるわけですな。こいつをお借りしよう、そういうわけであります。
あ、ちなみに「じゃあ$_POSTの中身を直接弄ったらええんちゃうのん?」というのもあるかと思いますが、「replace_post_exp」が働くのは「編集画面が表示される前」なのであります。つまりはデータベースに既に書き込んだ後。おそらくですけれどね。
これじゃあ弄ることはできませんね。
とりあえずは記事に「記事テスト」と入れて$_POSTの中身を観察してみます。
コードにするとこんな感じですね。
function replace_post_exp($exp) {
vbt($_POST,"post");
return $exp;
}
add_filter('excerpt_save_pre', 'replace_post_exp');

お、見つけました。「$_POST[“content'”]」の中に記事の内容が詰まっているようです。ひゃっはー。
さて、私がよく使う感想の描き方の中身をそのままコピペして観察します。
 |
物語が一気に加速して目眩すら感じる「ノーゲーム・ノーライフ 三巻」書評 | 頭のなか果汁だらけ |
これなんてどうでしょ。
["content"]=> string(5602) "http://www.amazon.co.jp/%E3%83%8E%E3%83%BC%E3%82%B2%E3%83%BC%E3%83%A0%E3%83%BB%E3%83%8E%E3%83%BC%E3%83%A9%E3%82%A4%E3%83%953-%E3%82%B2%E3%83%BC%E3%83%9E%E3%83%BC%E5%85%84%E5%A6%B9%E3%81%AE%E7%89%87%E5%89%B2%E3%82%8C%E3%81%8C%E6%B6%88%E3%81%88%E3%81%9F%E3%82%88%E3%81%86%E3%81%A7%E3%81%99%E3%81%8C%E2%80%A6%E2%80%A6-MF%E6%96%87%E5%BA%ABJ-%E6%A6%8E%E5%AE%AE%E7%A5%90/dp/4840149585/ref=sr_1_2?ie=UTF8&qid=1359299011&sr=8-2</pre> <blockquote title=""Amazon.co.jp:" cite=""http://www.amazon.co.jp/%E3%83%8E%E3%83%BC%E3%82%B2%E3%83%BC%E3%83%A0%E3%83%BB%E3%83%8E%E3%83%BC%E3%83%A9%E3%82%A4%E3%83%953-%E3%82%B2%E3%83%BC%E3%83%9E%E3%83%BC%E5%85%84%E5%A6%B9%E3%81%AE%E7%89%87%E5%89%B2%E3%82%8C%E3%81%8C%E6%B6%88%E3%81%88%E3%81%9F%E3%82%88%E3%81%86%E3%81%A7%E3%81%99%E3%81%8C%E2%80%A6%E2%80%A6-MF%E6%96%87%E5%BA%ABJ-%E6%A6%8E%E5%AE%AE%E7%A5%90/dp/4840149585/ref=sr_1_2?ie=UTF8&qid=1359299011&sr=8-2""> <span>ゲームで全てが決まる世界【ディスボード】――人類種の王となった異世界出身の天才ゲーマー兄妹・空と白は、世界第三位の大国『東部連合』に、その大陸全領土と"人類種の全権利"を賭けて行う起死回生のゲームを仕掛けたが、直後。謎の言葉を残して空は消えてしまった――……引き離された二人で一人のゲーマー『 (くうはく)』 消えた空の意図、残された白、人類種の運命は! そして獣耳王国(パラダイス)の行方は――!? 「言ったろ"チェックメイト"って。あんたらは……とっくに詰んでたのさ」 対獣人種戦決着へ――薄氷を踏む謀略が収束する、大人気異世界ファンタジー第三弾! </span> <cite>via: <a href=""http://www.amazon.co.jp/%E3%83%8E%E3%83%BC%E3%82%B2%E3%83%BC%E3%83%A0%E3%83%BB%E3%83%8E%E3%83%BC%E3%83%A9%E3%82%A4%E3%83%953-%E3%82%B2%E3%83%BC%E3%83%9E%E3%83%BC%E5%85%84%E5%A6%B9%E3%81%AE%E7%89%87%E5%89%B2%E3%82%8C%E3%81%8C%E6%B6%88%E3%81%88%E3%81%9F%E3%82%88%E3%81%86%E3%81%A7%E3%81%99%E3%81%8C%E2%80%A6%E2%80%A6-MF%E6%96%87%E5%BA%ABJ-%E6%A6%8E%E5%AE%AE%E7%A5%90/dp/4840149585/ref=sr_1_2?ie=UTF8&qid=1359299011&sr=8-2"" target=""_blank"">Amazon.co.jp: ノーゲーム・ノーライフ3 ゲーマー兄妹の片割れが消えたようですが……? (MF文庫J): 榎宮祐: 本</a></cite></blockquote> 早いもので、このシリーズも三巻目に突入した。 独特な地文も、若干混乱するカメラワークもここまで来ると慣れてきて快感に変わってくる頃合い。 <!--more--> 面白い物で、最初は「筆力がまだまだ」とか言っておきながら、その文章に私の方が慣れてしまった。ただ、やっぱりカメラワークの点で混乱する描写が多々ある。ここらへんはやっぱりこれからに期待すると言うことなのかな。 さて、物語は一気に一つ目の山場を迎えた。強大な領土と強力な力を持つ獣人族とのゲーム。スピード感溢れる描写と、著者らしい軽い文体が心地良い。
さて、中身をそのままコピーしてきたが、実際はこんな感じ。観察すると「p」や「br」タグがないこと、「p」に当たる部分は空改行があることがわかりますね。ここで必要の無いものを選定してみます。
- 空改行の行
- blockquote、citeなどで囲われている部分
- httpから始まる行
- moreタグ
ここまで来ればもう一息。こいつらを全てクリアするために、文字列操作が必要ですな。こんなもん正規表現です。正規表現の説明については
 |
サルにもわかる正規表現入門 |
様に任せます。凄くわかりやすいです。超絶お世話になりました。
動作のテストについては、
 |
PHP正規表現チェッカー |
をよく利用しています。リアルタイムで結果がみれるのでとても助かります。
といいますかさっそく利用していきましょう。

そのままぶち込みます。
とりあえずは「タグとタグで囲まれている部分」を削除してみましょうか。

preg正規表現にチェックをつけます。

まずは下準備。「//」で囲まれた部分に正規表現の記述をしていきます。後ろの「ium」は、それぞれ「i」=アルファベット大文字小文字無視、「u」UTF-8での処理、「s」改行を無視して最初から最後まで走査となります。UTF-8での処理が何故入っているかというと、こうしないと日本語が文字化けしちゃうから、なんですね。UTF-8以外で処理しちゃうと、日本語が上手くしょりできないんです。今まさに文字化けしてますね。「//」 だけだとこうなっちゃいます。
とりあえず「タグ」で囲われてる部分の条件を考えつつ適当に正規表現を記述。
なんとなく、そうですね。「<で始まり、その次の</」で終わる物全部なんてどうです?

お、良い感じじゃ無いでしょうか。HTMLタグで始まった物は最後がなんであれかならずHTMLタグで終わるはず、という適当な考えが当てはまりました。
もう少し弄って、こう
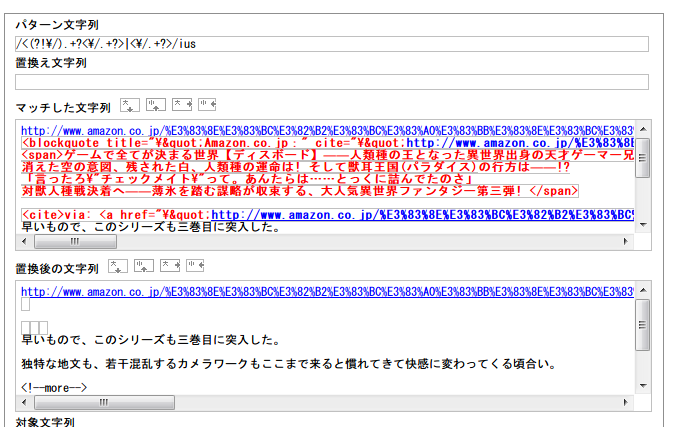
「/<(?!/).+?</.+?>|</.+?>/ius」でいこうと思います。「<hogehoge>から始まって最初の</hogehoge>」、そして「</hogehoge>」単体です。
「/」は、正規表現を「/」で囲っているので「こいつはただのスラッシュさんだよ」と教えるためのもの。エスケープ処理というらしいです。
で、「<(?!/)」っていうのが少し難しいカモですが、「(?!)」は先読み否定と言います。「(?!)でくくられた単語の前の一文字はマッチしない」という意味です。つまり「<(?!/)」を言い換えると「/の前に<があったら無視する」という意味。これで確実にhtmlタグの開始から始められるわけですね。
「.+?」も面白い動きをします。「.」が全てに当てはまる。何でも良いってわけですね。
「+」はそれが一個以上の繰り返し。
「.+」と合わせれば「全ての文字の、一個以上繰り返しずっと」という意味になります。「全ての文字の繰り返し」という表現、面白いですね。こういう概念的というか、変な言葉好きですよ私。htmlタグは絶対に一個以上の文字が入るのでokです。
そして「?」は「?の前の一文字が有りでも無しでもマッチする」という意味です。ちょっと難しい。
つまりこの「.+?」って奴は、一文字進む度に「.」であり「+」であり「?」でもある、という条件になります。わ、わけがわからねえ。
こういうのはテストするにかぎります。
挙動をかくにんしてみましょう。
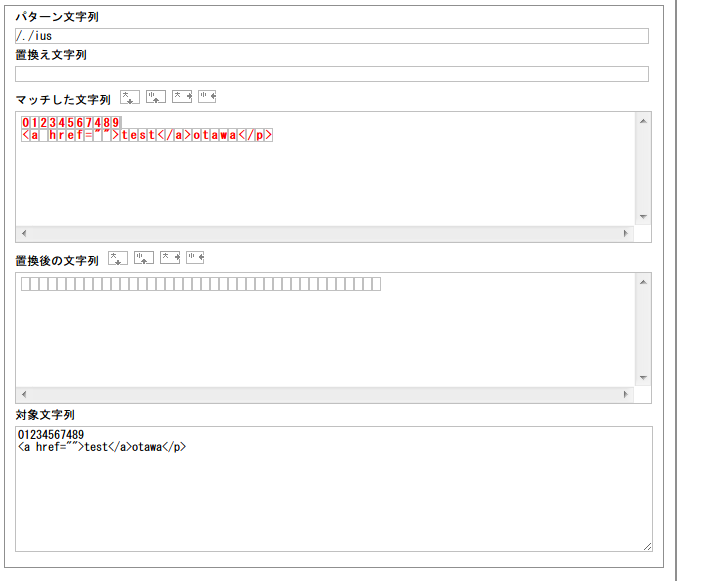
まずは「.」から。うん、全てにあってますね。けれども良く見ると「一文字ずつ」マッチしていますよ。言い換えると「なんでも良い一文字」にマッチしているわけです。
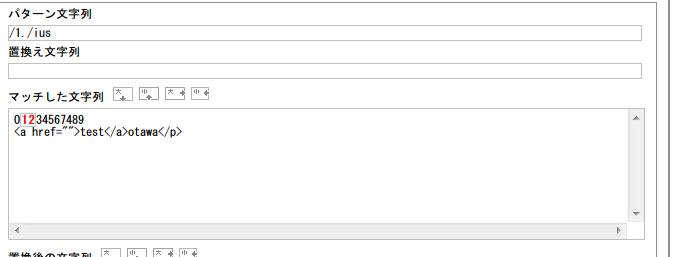
こうすると「『1』と全ての文字」の二文字の組み合わせ。おお、わかりやすい。
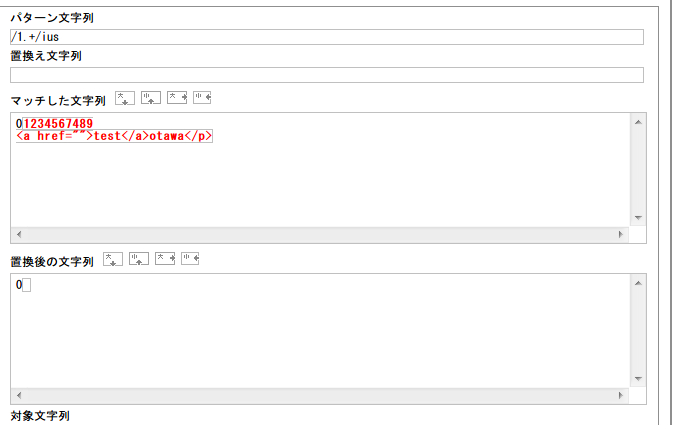
「+」をつけると繰り返しだからそこから全ての文字。
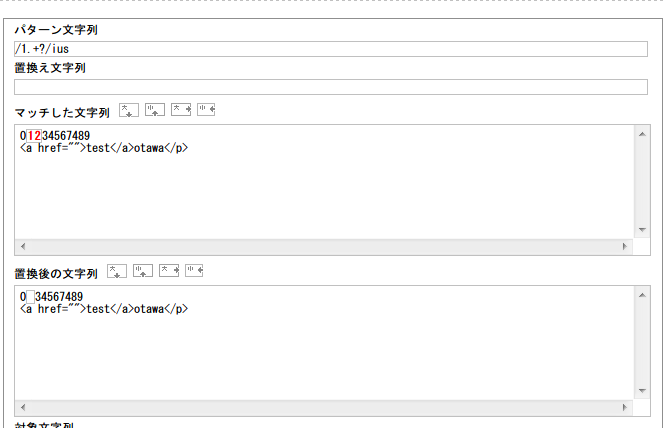
「?」をつけるとこうなる。こうやって色々試行錯誤してるのが一番楽しいです。これは「1.+」でもありますけれど、「1.」にも当てはまってますよね。つまり「1.+?」という条件に合致しているのです。
で、これを応用して「?」の次をこうします。
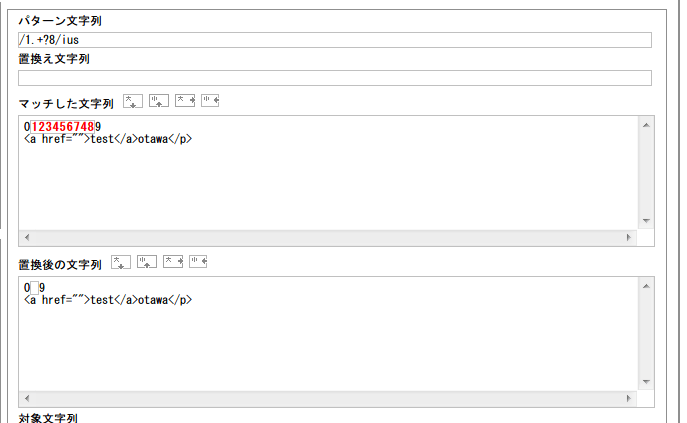
1から8まで一気にマッチ。「?」の動きに注目すれば簡単です。これは「1.+8」という条件にはあってますけれど、「1.8」という条件には当てはまりません。だから8が現れるまで全てにマッチします。
こんな感じでガシゴシお目当ての結果になるまでトライ&エラーを繰り返します。
あとはこの容量でガスゴシ削っていきますよ。
function replace_post_exp($text) {
$text = preg_replace("/<(?!/).+?</.+?>|</.+?>/ius", "", $_POST['content']);
$text = preg_replace("/http.+?(?=[ tnrfv ]|$)/ium", "", $text);
$text = preg_replace("/^rn/ium", "", $text);
$text = mb_substr($text, 0, 200, 'utf-8');
return $text;
}
add_filter('excerpt_save_pre', 'replace_post_exp');
そして完成したのがこちら。
htmlタグを除去した後、アドレスのみの行を削除、そのあと改行だけの行を削除、と段階にわけてます。「$text = mb_substr($text, 0, 200, ‘utf-8’);」は最初から200文字以降を無視する、というものですね。
これで記事をとうこうしてみます。
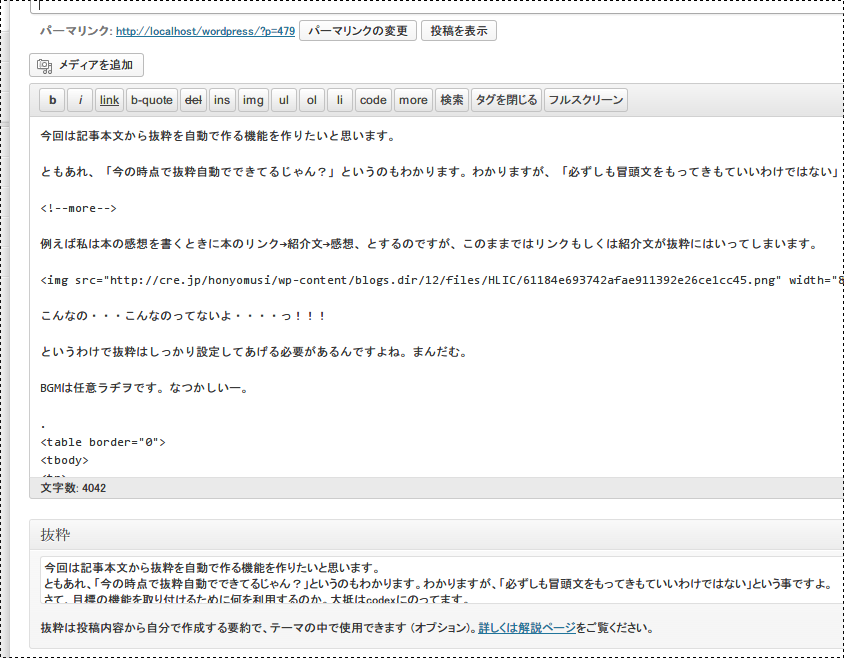
しっかりと入っていることがわかります。
しかし、たまに意図と違う抜粋になることもあります。完璧な自動化にはまだまだコードを練らなければいけませんね。というわけで手動で変更。
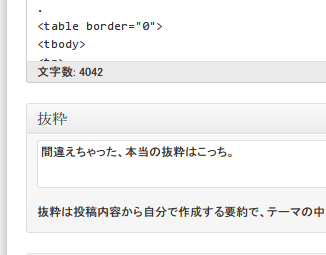
で、更新。
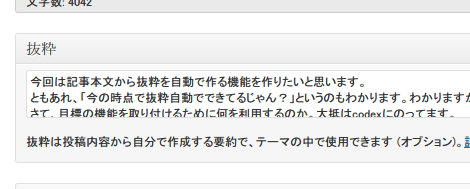
oh・・・・
このままだとどんな抜粋であれ無理矢理本文を弄った物が表示されるようになってしまっているのです。
function replace_post_exp($text) {
if ($text == "") {
$text = preg_replace("/<(?!/).+?</.+?>|</.+?>/ius", "", $_POST['content']);
$text = preg_replace("/http.+?(?=[ tnrfv ]|$)/ium", "", $text);
$text = preg_replace("/^rn/ium", "", $text);
$text = mb_substr($text, 0, 200, 'utf-8');
}
return $text;
}
修正しました。抜粋の部分が空欄だった場合のみ、このコードは効果を発揮します。
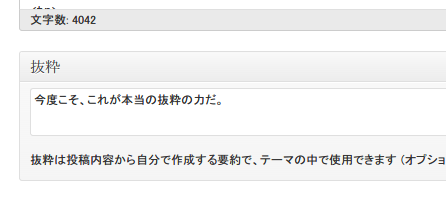
今度はちゃんど動作してますヤッター!!